
LemonSlice 2.1 Flash

Deploy an avatar that answers questions, guides customers, and drives meaningful conversations 24/7.
LemonSlice 2.1 Flash: A new benchmark in interactive avatars
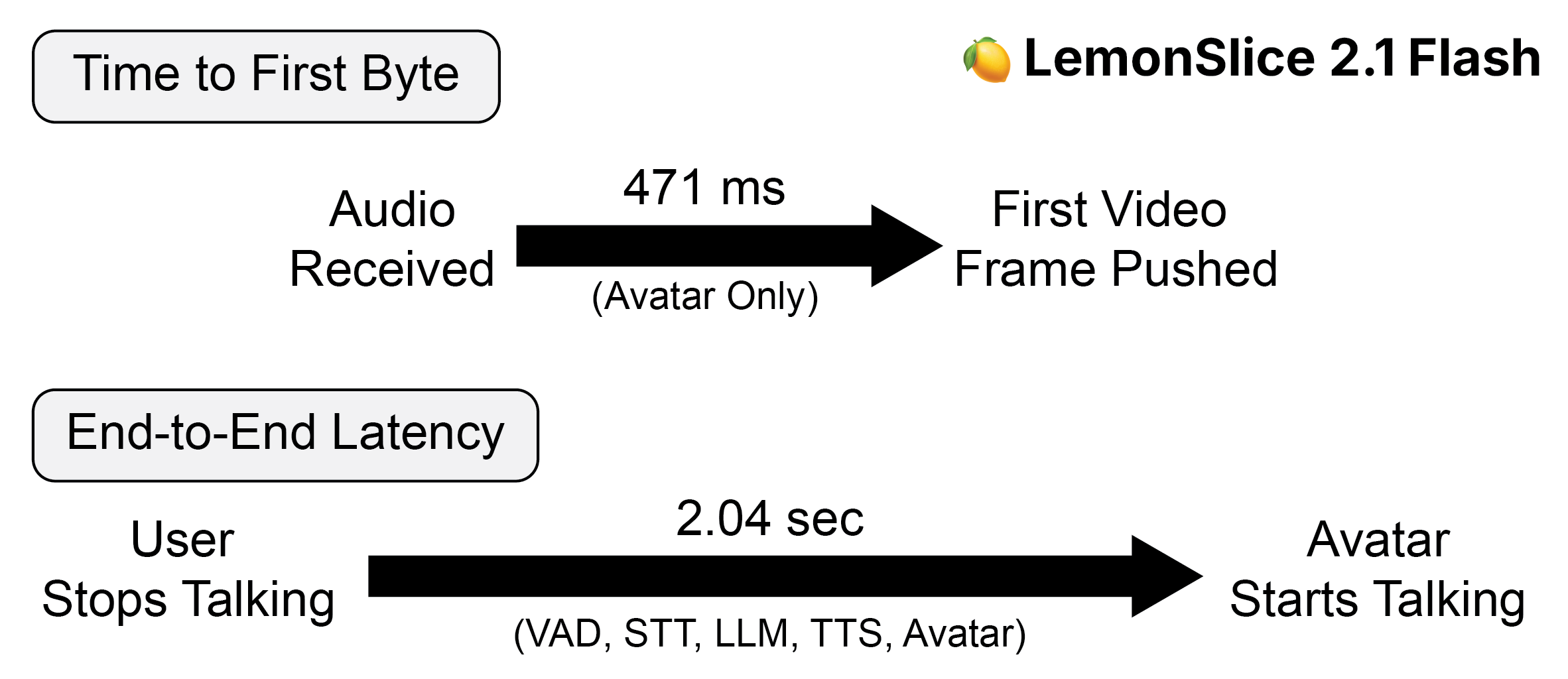
Today, we’re announcing LemonSlice 2.1 Flash, a video diffusion transformer model (DiT) and inference framework optimized for real-time, interactive avatars with state-of-the-art latency. Leveraging a novel model architecture and system-level optimizations, LemonSlice 2.1 Flash surpasses comparable avatar models in end-to-end latency benchmarks, while also offering key advantages as a one-stage DiT-based pipeline. We report an average time-to-first-byte of 471ms, measured from the time the first conditional audio chunk is received. When paired with third-party TTS, LLM, and STT components, LemonSlice 2.1 Flash achieves an average end-to-end response latency of 2.04s, enabling deployment in latency-sensitive applications.
Optimized for Speed
We previously released LemonSlice 2, a 20-billion parameter real-time avatar model that runs on a single GPU. Key features included zero-shot avatar generation from a single image, the ability to animate any style of character, expressive gestures, and infinite-length generation without error accumulation. Our LemonSlice 2.1 model release introduced additional controls, including gesture and emotion manipulation so that avatars can update their behavior in real-time to a conversation's context.
LemonSlice 2.1 Flash builds upon this foundation with targeted changes that reduce end-to-end latency. Achieving this required a system-level approach, with optimizations spanning both model architecture and runtime execution. Rather than relying on a single improvement, we focused on reducing overhead across each stage of the inference pipeline.
At the model level, we introduce modifications to the diffusion transformer that enable more efficient incremental inference, reducing per-step compute without degrading output quality. The VAE decoding path was similarly optimized to minimize latency during frame generation.
At the systems level, we leverage CUDA graph capture to reduce CPU-side dispatch overhead and streamline GPU execution. We also implement a tightly coordinated CPU-GPU execution model that minimizes idle time and overlaps compute with data movement where possible.
Finally, our runtime incorporates purposeful queue management to ensure high throughput and avoid bottlenecks across asynchronous components such as audio processing and model inference. Together, these optimizations reduce both time-to-first-byte and end-to-end latency. We run inference on Modal, who's been a great partner in our quest for ultra-low latency.
In controlled testing, we find that LemonSlice 2.1 Flash delivers an average time-to-first-byte of 471ms. When paired with fast third-party STT, LLM, and TTS components, LemonSlice 2.1 Flash achieves an average end-to-end response latency of 2.04s.
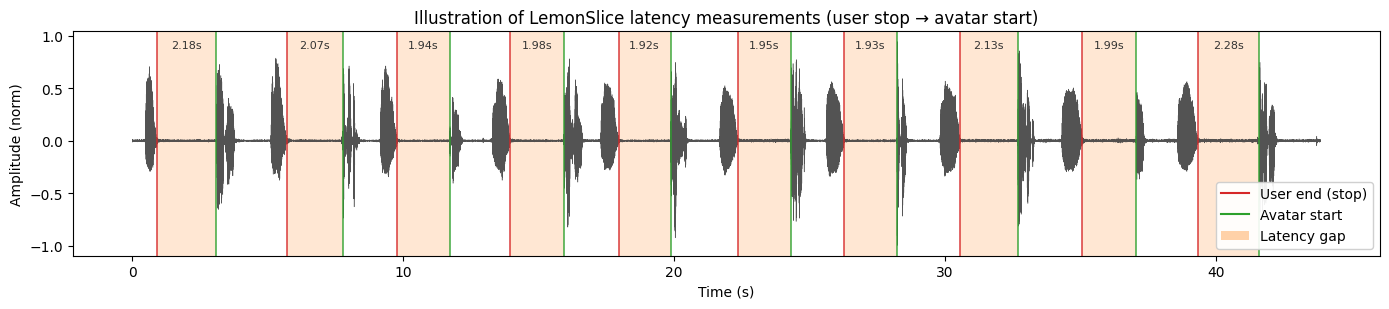
Quantitative Latency Measurement
To measure end-to-end latency, we connect to a LemonSlice-powered avatar using the publicly available LiveKit Agents framework. Each call consists of 10 automated back-and-forths between a synthetic client and a locally hosted LiveKit agent. A prerecorded audio clip containing the utterance “hello” is played into the call, and the avatar is instructed via the LLM’s system prompt to respond with a random number. To minimize bias, we repeat data collection across 5 calls (N=50 total responses), with the agent reinitialized each time.
Speech segments are extracted from each call by applying an RMS envelope to raw audio with hysteresis thresholding. We define the end-to-end latency of each response as the time difference between the end of a user's utterance and the onset of the corresponding avatar response.
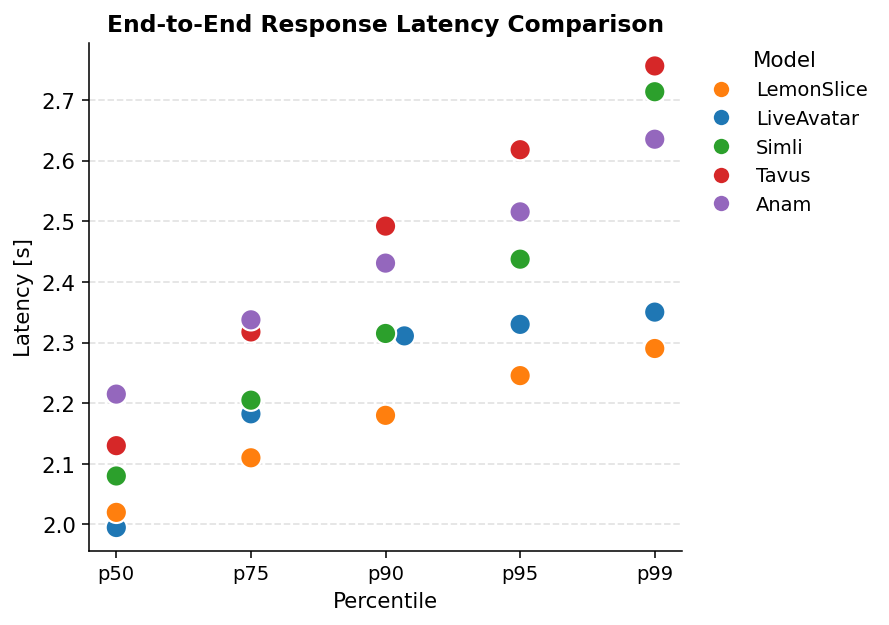
Comparison with Other Models
We compare LemonSlice 2.1 Flash against other commercially available avatars by replacing the LiveKit AvatarSession with the corresponding LiveKit integration. All data was collected on the same date to minimize bias (April 15, 2026), and using the same STT/LLM/TTS models (see Appendix). Only the corresponding AvatarSession object was changed.
We find that LemonSlice 2.1 Flash is significantly faster than Tavus Phoenix-4 (p=8.1e-5; two-sided Welch t-test) and Anam Cara-3 (p=3.2e-10), while having comparable latency to LiveAvatar (p=0.83) and Simli (p=0.19). LemonSlice 2.1 Flash is also the fastest when measuring p75, p90, p95, and p99 percentiles.
We note that LemonSlice 2.1 Flash is also a general purpose DiT model that can work with any reference image, does not require per-avatar fine-tuning or training, and also supports precise in-call gesture and emotion control.
Appendix
To make our results reproducible by the broader community, we share the LiveKit agent and avatar configurations of third-party models used for testing. The LLM agent prompt was "Always respond with a random number between 1 and 100. Never repeat a number until you have reused them all." With other system prompts, latencies may be slower due to additional LLM processing. We note that hosting the LiveKit agent locally likely introduced additional latency in the system that would not be encountered in production environments.
Continue Reading



Try LemonSlice 2.1 Flash Now
Try the new model on our homepage for FREE without login





